SeMask: Semantically Masked Transformers for Semantic Segmentation
Dec 2021· ,,,,,,·
0 min read
,,,,,,·
0 min read
Jitesh Jain
Anukriti Singh
Nikita Orlov
Zilong Huang
Jiachen Li
Steven Walton
Humphrey Shi
Abstract
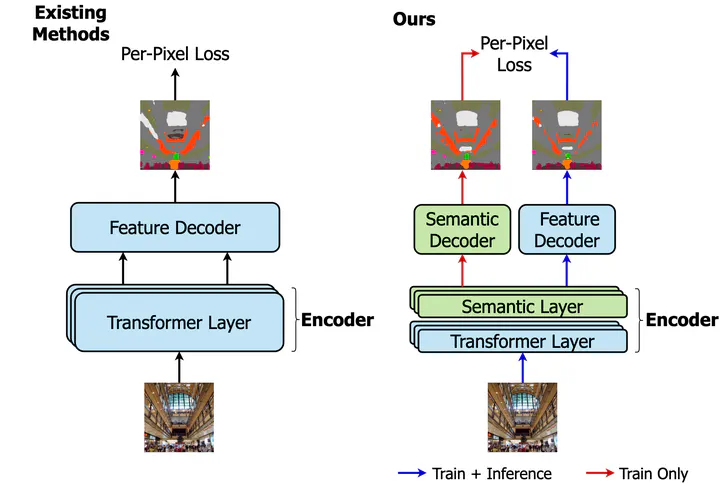
Finetuning a pretrained backbone in the encoder part of an image transformer network has been the traditional approach for the semantic segmentation task. However, such an approach leaves out the semantic context that an image provides during the encoding stage. This paper argues that incorporating semantic information of the image into pretrained hierarchical transformer-based backbones while finetuning improves the performance considerably. To achieve this, we propose SeMask, a simple and effective framework that incorporates semantic information into the encoder with the help of a semantic attention operation. In addition, we use a lightweight semantic decoder during training to provide supervision to the intermediate semantic prior maps at every stage. Our experiments demonstrate that incorporating semantic priors enhances the performance of the established hierarchical encoders with a slight increase in the number of FLOPs. We provide empirical proof by integrating SeMask into each variant of the Swin-Transformer as our encoder paired with different decoders. Our framework achieves a new state-of-the-art of 58.22% mIoU on the ADE20K dataset and improvements of over 3% in the mIoU metric on the Cityscapes dataset. The code and checkpoints are publicly available at
.
Type
Publication
NIVT Workshop @ICCV 2023<\mark>